
minstory
Python 카톡 대화 단어 빈도 구하기 본문
재미 삼아서 친구와 한 카톡 내용을 분석해보았다.
(모바일 카톡에서 내보내기한 txt파일 활용. pc카톡에서 내보내기한 파일은 대화 초반부분이 없다.)
파이썬 정규표현식 활용은 처음인데, 확실히 텍스트 데이터 다룰 때 유용하다.
내가 입력한 단어의 빈도를 구해서
Pycharm에서 출력하고 엑셀파일로도 저장한다.
import os
import re
from pandas import DataFrame
BASE_DIR = os.path.dirname(__file__)
CHAT_DATA_DIR = os.path.join(BASE_DIR, 'chat_data')
words = input('공백을 구분자로 빈도를 알고 싶은 단어를 입력해주세요 : ').split()
wordTable = {key:[] for key in words}
with open(os.path.join(CHAT_DATA_DIR, "2021.05.20.친구.txt"), "r", encoding="utf-8") as f:
'''데이터 정제하기'''
data = f.read()
data = re.sub('\d+년 \d+월 \d+일 \D요일\n', '', data) #년월일 문장 제거
data = data.replace('\n', ' ')
sent_time = re.findall('\d+[.] \d+[.] \d+[.] 오\D \d+:\d+, ', data) #날짜시각 추출
data = [data]
for i in sent_time: #날짜시각을 기준으로 메세지 분리
temp = data[-1]
data.pop()
data.extend(temp.split(i))
data = data[1:]
'''정제된 데이터 txt파일 확인'''
with open(os.path.join(CHAT_DATA_DIR, "refined_data.txt"), "w", encoding="utf-8") as fw:
for line in data:
fw.write(line+'\n')
names = sorted({line.split(' : ')[0] for line in data}) #사용자 이름 추출
user_linesList = [[line.split(name+' : ')[1] for line in data if (name+' : ') in line] for name in names] #사용자 별로 문장 분류. ex)첫번째 list는 사용자1의 문장들
for user_lines in user_linesList: #ex)사용자1 문장들 부터 분석 시작
for word in words:
temp = 0
for line in user_lines:
temp += line.count(word)
wordTable[word].append(temp) #ex)사용자1의 단어1 빈도 추가
df = DataFrame(wordTable, index=names)
df.to_excel(os.path.join(CHAT_DATA_DIR, 'words_frequency.xlsx'))
print('='*3, '단어 빈도 분석 결과', '='*3)
print(df)
print('='*6, '총 메세지 수', '='*6)
for i in range(len(names)): #사용자 별로 메세지 개수 출력
number = len(user_linesList[i])
print(names[i], ':', number, '개')

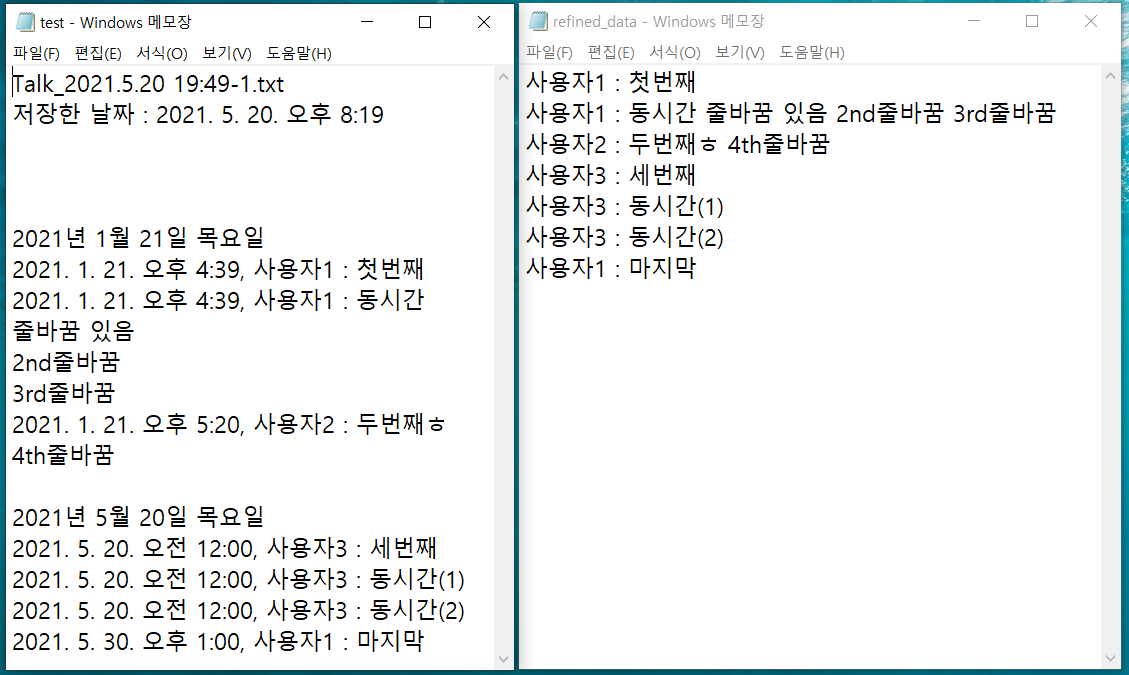
위는 예시 파일인데, 오른쪽의 refined_data를 보면 불필요한 문장을 삭제했고
줄바꿈 많은 메세지를 하나로 병합해서 사용자n이 말한 메세지임을 인식할 수 있게 하였다.
동시간에 보낸 메세지들도 잘 구분해놓은 것을 확인 할 수 있다.
*데이터 정제하고 단어 빈도 구하는 알고리즘이 효율적으로 보이진 않는다..
나중에 효율적인 알고리즘이 생각난다면 수정해봐야겠다.
위의 코드로는 특정 단어 빈도만 구할 수 있는데,
날짜시각을 리스트로 따로 추출해놨으니 추후에 카톡 시간대, 대화 간격도 분석할 수도 있겠다.
Comments